
[Paper Review] G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment (EMNLP 2023)
Published:
GPT-4로 NLG 평가하기
Abstract
Natural Language Generation (NLG) 분야는 automatic하게 평가하기가 어렵다. 기존 metric인 BLEU와 ROUGE는 창의성이나 다양성에서 평가를 하지 못하기에 사람과의 상관관계가 낮다. NLG의 경우 사람이 만든 정답 레이블이 없는 경우가 많기에, 최근 연구들에서는 large language models (LLMs)을 사용하여 NLG를 reference-free하게 평가하는 방법들이 제안되었다. 하지만 아직 LLM-based evaluator들이 더 작은 모델들보다 인간 평가와의 상관관계가 낮다. 따라서, 해당 논문에서는 chain-of-thought (CoT)과 form-filling을 사용한 G-Eval을 제안한다.
Introduction
NLG 시스템들이 생성하는 글들이 사람이 직접 쓴 글과 구별하기가 어려워지면서 NLG 모델들을 평가하는 것은 쉽지 않은 일이 되었다. 따라서, open-ended 생성 태스크에서는 특히 BLEU, ROUGE, METEOR와 같은 NLG 평가 metric들은 인간 평가와 상관관계가 낮은 것으로 알려졌다. 또한, 이러한 평가를 위해 새로운 task마다 reference 결과물을 얻는 것은 비용이 든다. 따라서, 해당 논문에서는 LLM을 사용하여 reference-free로 평가하는 방법을 제안한다. 해당 논문에서는 LLM이 고품질의 자연스러운 텍스트에 대한 정보를 이미 알고 있다는 가정하에 CoT와 form-filling을 통해 NLG 모델들을 평가한다.
Method
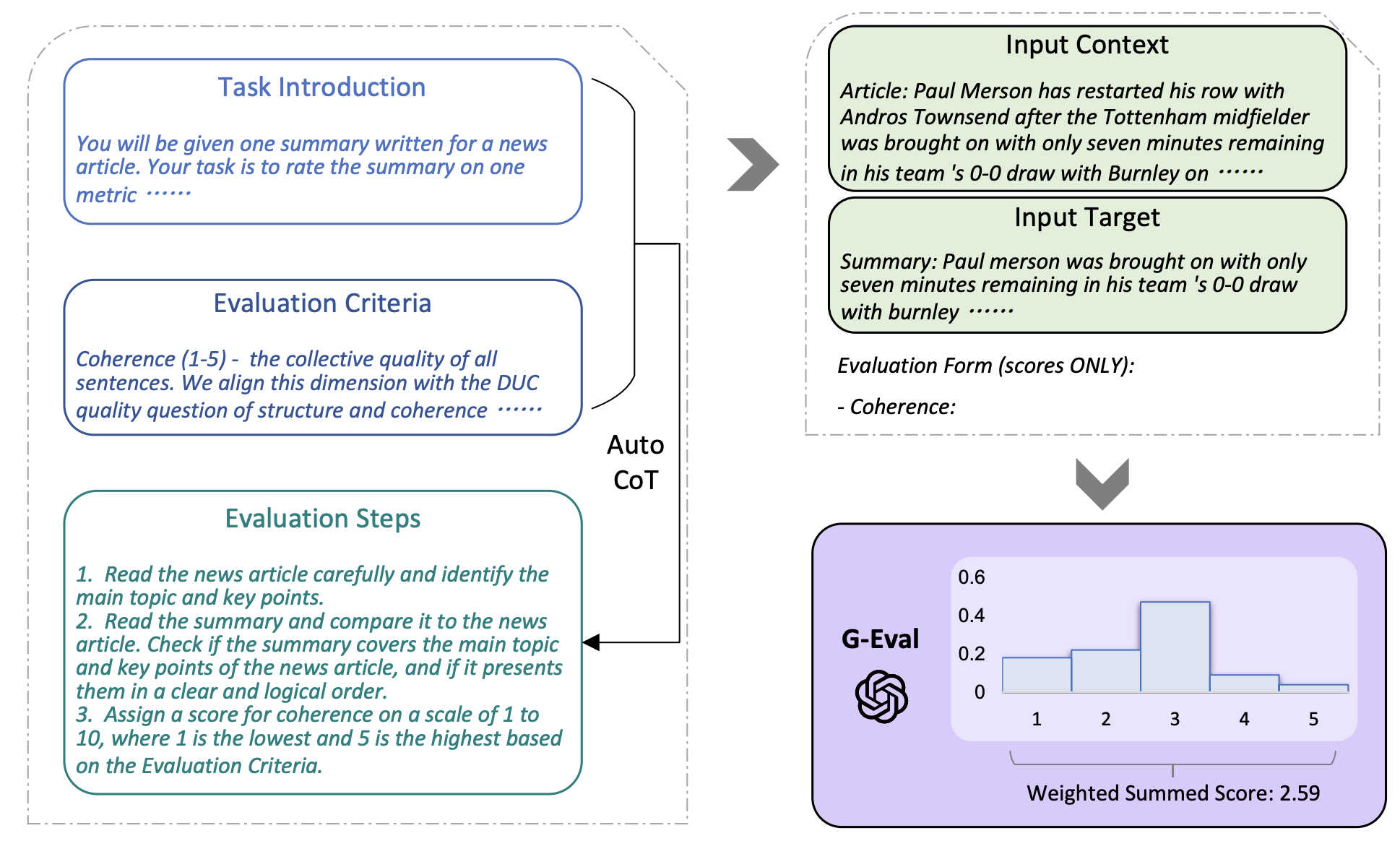
G-Eval은 프롬프트 기반 평가 모델이며, 3가지의 주요 컴포넌트를 가지고 있다. 첫 번째로, 평가해야하는 태스크의 정의와 평가 기준, 두 번째로, LLM이 디테일한 평가 방법을 설명하기 위한 CoT, 마지막으로 토큰 확률을 기반으로 평가하는 계산법이 있다.

먼저 평가하는 태스크와 해당 태스크를 평가하는 기준에 대한 설명이다. 위의 예시를 보면 요약 태스크를 정의하는 기준을 설명한다.

그 후에, 요약 태스크를 어떤 기준에 대해 평가해야 하는지 평가 기준에 대해서 설명을 해준다.

입력으로 위의 태스크 정의와 평가 기준을 넣어주면, LLM이 자동으로 어떻게 해당 태스크를 해당 기준에 대해서 평가해야 하는 지에 대한 과정을 알려준다.
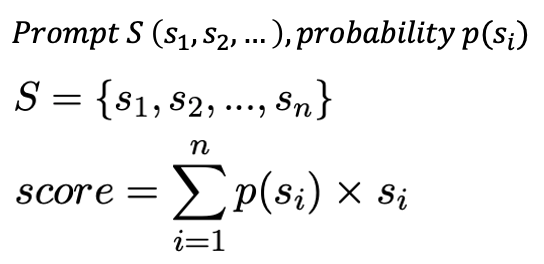
해당 평가 기준에 대해서 평가가 끝나면, 모델은 form-filling을 통해 숫자를 출력하게 된다. 하지만 위와 같은 방식으로 평가를 진행하면 두 가지의 문제점이 있었다. 먼저, 특정 점수가 너무 많이 나오는 현상이 발생했다. 예를 들어 0~5점의 평가를 하면, 모델이 대부분 3점으로 평가하였다. 또한 LLM이 대부분 정수를 출력했기에, 디테일한 평가가 부족했다. G-Eval은 위와 같은 weighted sum을 통해서 이 문제를 극복하고자 했다. 각 점수가 출력되는 확률을 곱해줌으로써, 더 많이 등장한 점수에 weight를 부과하고자 했다. 사실 이 weighted sum 방식은 여러 번 평가 후에 평가 점수들을 평균 낸 것과 동일하다.
Experiments
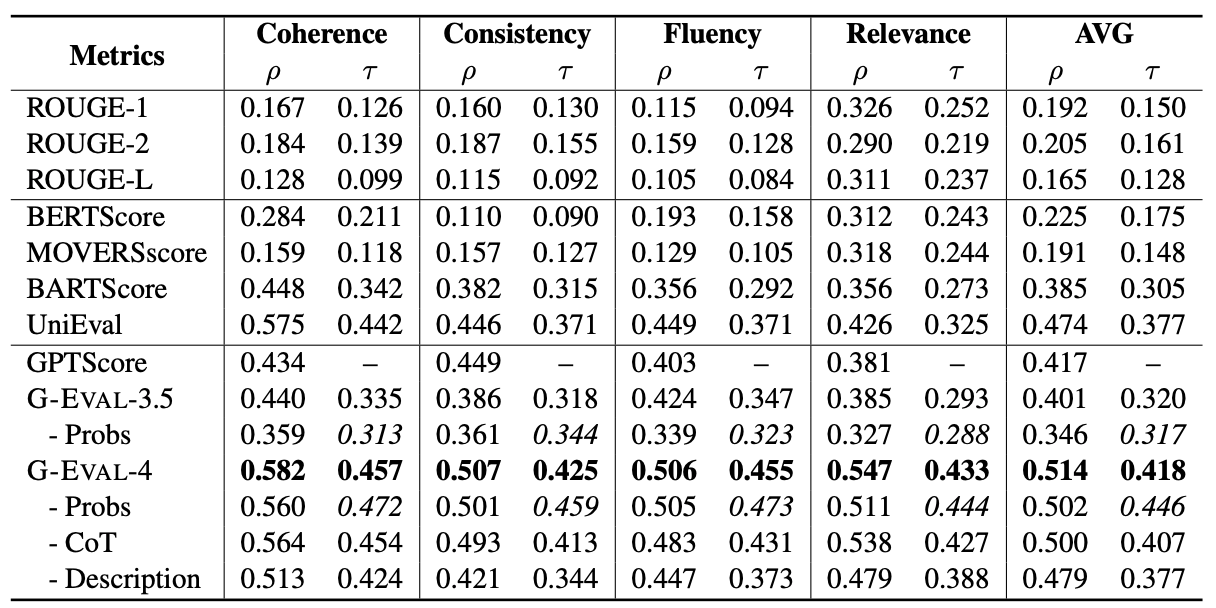
그 결과, 기존의 GPT 기반의 평가 방식인 GPTScore에 비해 훨씬 사람과 유사한 평가를 할 수 있었다. 위의 표는 SummEval 벤치마크를 사용하였으며, 사람과의 유사도를 평가하기 위해서 summary-level Spearman과 Kendall-Tau를 사용하였다. 위의 표를 보면, G-Eval-3.5에 비해 G-Eval-4에서 훨씬 높은 유사도를 보이는 것을 볼 수 있다. Ablation study가 G-Eval-4에서는 Probs, CoT, Description에서 모두 이루어졌지만, G-Eval-3.5에서는 Probs에 대해서만 ablation study가 이루어졌다.
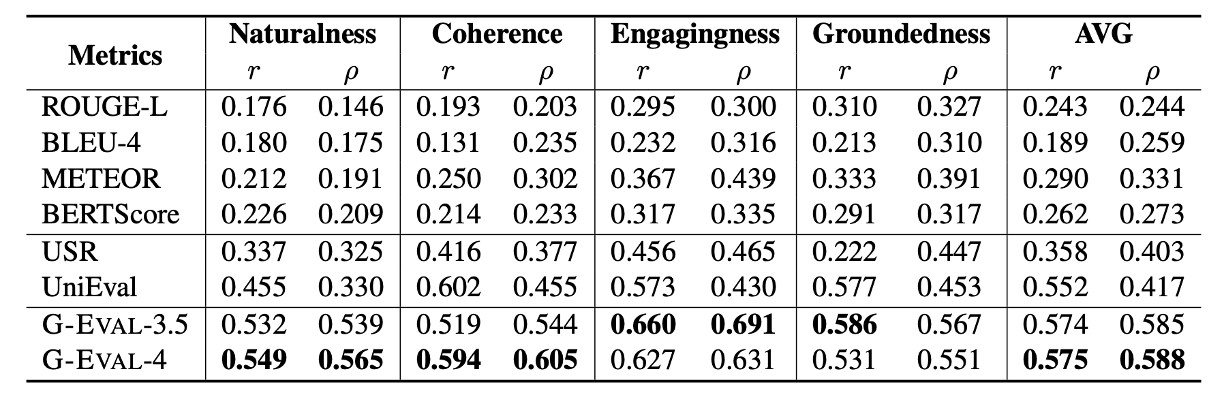
Topical-Chat 벤치마크에서도 기존의 모델들에 비해 훨씬 높은 유사도를 보인다. 해당 표에서 Coherence 부분에서 UniEval이 GPT-4보다 높은 점수를 보이지만 볼드 처리가 잘못되었으며 Groundedness에서는 볼드 처리가 되지 않았다.
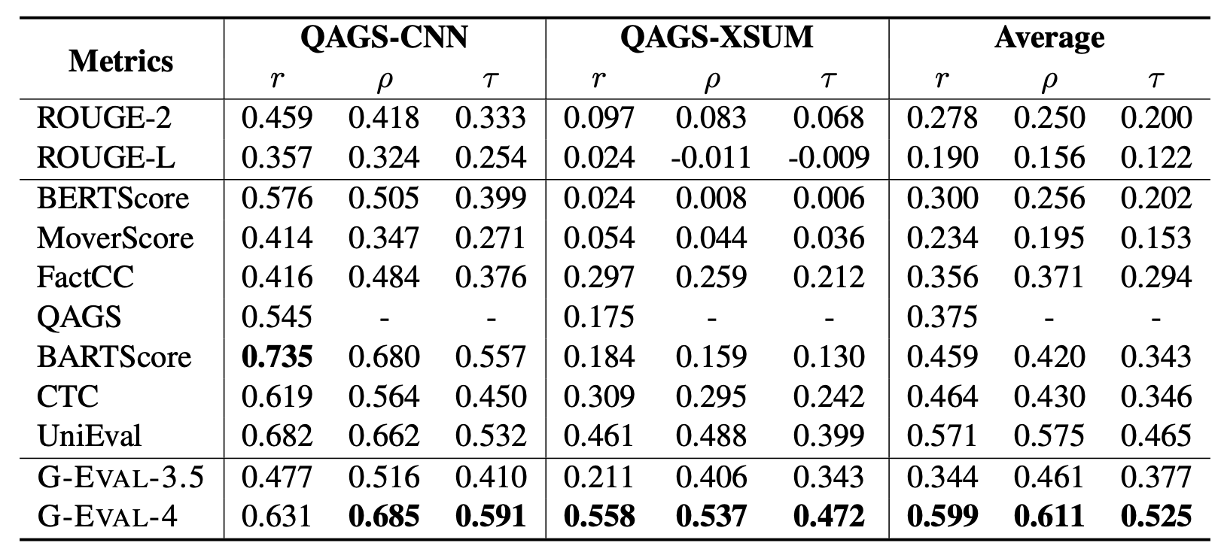
QAGS 벤치마크에서도 마찬가지로 대부분 가장 높은 유사도를 보였다. BARTScore의 경우 QAGS-CNN에서는 가장 높은 유사도를 보였지만 QAGS-XSUM에서는 굉장히 낮은 유사도를 보이는 것으로 보아, G-Eval이 모든 지표에서 안정적으로 평가가 가능하다는 것을 보여준다.
Analysis
Will G-Eval prefer LLM-based outputs?
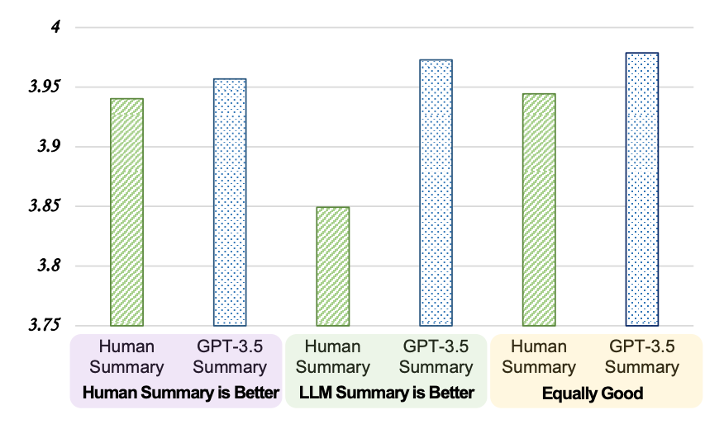
G-Eval이 LLM이 생성한 요약문을 더 선호할 수 있다고 한다. 기존에 사람이 만든 요약문과 GPT-3.5가 생성한 요약문을 평가한 결과를 모은 데이터 셋을 사용하여, G-Eval에 적용을 시켜보았다. 위의 그래프를 보면, 사람이 생성한 요약문이 더 좋다고 레이블링이 되어있는 요약문을 G-Eval로 각각 평가를 했을 때, GPT-3.5가 생성한 요약문이 더 좋다고 평가하였으며, 사람이 생성한 요약문과 GPT-3.5가 생성한 요약문이 비슷하다고 레이블링이 되어있는 요약문도 G-Eval은 GPT-3.5가 생성한 요약문을 더 선호하였다. 이를 통해, G-Eval이 LLM이 생성한 요약문을 더 선호할 수 있다는 가능성을 제시했다. 해당 논문에서는 그 이유에 대해서 2 가지로 분석하였다. 먼저 좋은 퀄리티의 시스템에서 나온 NLG 출력물들은 실제로 평가가 어렵다는 것이었다. 해당 데이터 셋을 만든 논문에서도 inter-annotator 간의 상관관계가 굉장히 낮다고 한다 (Krippendorff’s alpha at 0.07). 두 번째로, LLM이 요약문을 생성할 때와 평가할 때, 같은 기준을 사용할 수 있기에 실제로 편향이 존재할 수도 있다는 것이다. 따라서, LLM을 LLM의 점수를 통해 강화학습을 하는 것은 편향이 생길 수 있기에 주의를 해야한다.
Conclusion
해당 논문에서는 LLM을 통해 사람과 상관관계가 높은 평가 방법을 제시한다. G-Eval은 reference-free로 어떠한 기준에서든 평가 단계를 생성하여 평가할 수 있기에 굉장히 좋은 평가 방법이지만, 오픈소스 모델인 UniEval과 두드러지게 좋은 성능을 보이지는 않기에 아직 한계가 있다고 생각한다. 또한 실제 요약 평가 코드에서 Fluency의 평가가 다른 지표와 달리 0~3 점으로 설정이 되어있었는데, 이 부분은 의아하다.